我的第一篇 IT 邦文章,就來介紹一下最近工作研究的東西吧!我是資訊領域的新手,以前做的偏硬體,後來在做 AI ,發現自己對網頁也很有興趣(反正技術都可互相應用不是嗎?)
最近工作加入資料處理的團隊,需要做網頁爬蟲,才了解有 robots.txt 的存在,那我們就來看看這是什麼吧!
robots.txt 為存放於網站根目錄下的文字檔案(.txt),為 ASCII 編碼,如農業部官網的 robots.txt 如下: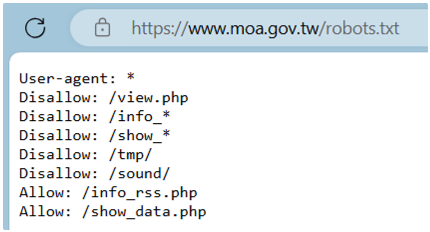
這是用來告訴爬蟲機器人,哪些網站可以造訪,哪些網站不能造訪。如果是善良的機器人,會先造訪 robots.txt,並遵循內容進行爬蟲,如果是比較壞心的機器人,就不會遵守 robots.txt 的準則了。
但其實 robots.txt 不是一個強制性的規定,是一種約定成俗的準則,所以這也不代表可以保護你的網頁隱私。
要怎麼寫 robots.txt 的內容呢?主要是幾個指令:Allow、Disallow 和 Crawl-delay。
如果你允許讓所有機器人進行爬蟲:
User-agent: *
Disallow:
或
User-agent: *
Allow:/
如果你只想允許特定的機器人:
User-agent: 機器人名稱
Allow:
如果你想要禁止所有的機器人:
User-agent: *
Disallow: /
如果你想要禁止機器人造訪特定的目錄:
防止所有的機器人:
User-agent: *
Disallow: /路徑/
禁止特定的機器人:
User-agent: 機器人名稱
Disallow: /路徑/
如果你想要設定特定的檔案類型或路徑,如:
User-agent: *
Disallow: /* .副檔名$
這裡「*」表示萬用字元,「$」表示網址結尾,像是「/files」會等於「/files*」。
提醒 robots.txt 是有區分大小寫的!
而 Crawl-delay 的用法,可以設定機器人對每個請求應等待的時間,以毫秒為單位,如:
Crawl-delay: 5
表示等待 5 毫秒。
有些 robots.txt 會有網站地圖(Sitemap),可以讓機器人依循去造訪網頁,就不會錯過一些內容,但也不是強制要依照該順序去爬資料。網站地圖是 XML 檔案的路徑,如 Booking.com robots.txt 中的網站地圖: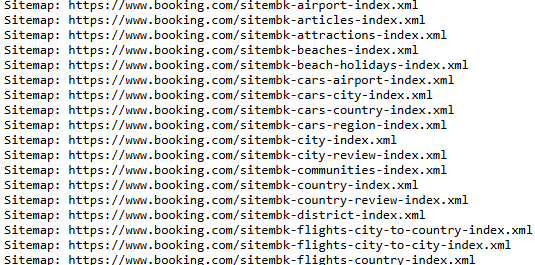
簡單介紹 robots.txt 的指令和它的用途,如果有做爬蟲機器人,可以遵守 robots.txt 的內容,當個乖寶寶機器人唷!
 Eunice
Eunice

 iThome鐵人賽
iThome鐵人賽